1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
import csv
import time
import random
import urllib3
import requests
from lxml import etree
from fake_useragent import UserAgent
urllib3.disable_warnings()
def get_company_id(page_url):
headers = {
"User-Agent": UserAgent(verify_ssl=False).random,
"Connection": "close",
"cookie": ""
}
html = requests.get(page_url, headers=headers, verify=False).text
tree = etree.HTML(html)
all_company_id = tree.xpath('//*[@id="search"]/div[2]/div/div/div[2]/div[1]/a/@href')
for company_id in all_company_id:
company_id = company_id.split('/')[-1]
pares_company_info(company_id)
time.sleep(1)
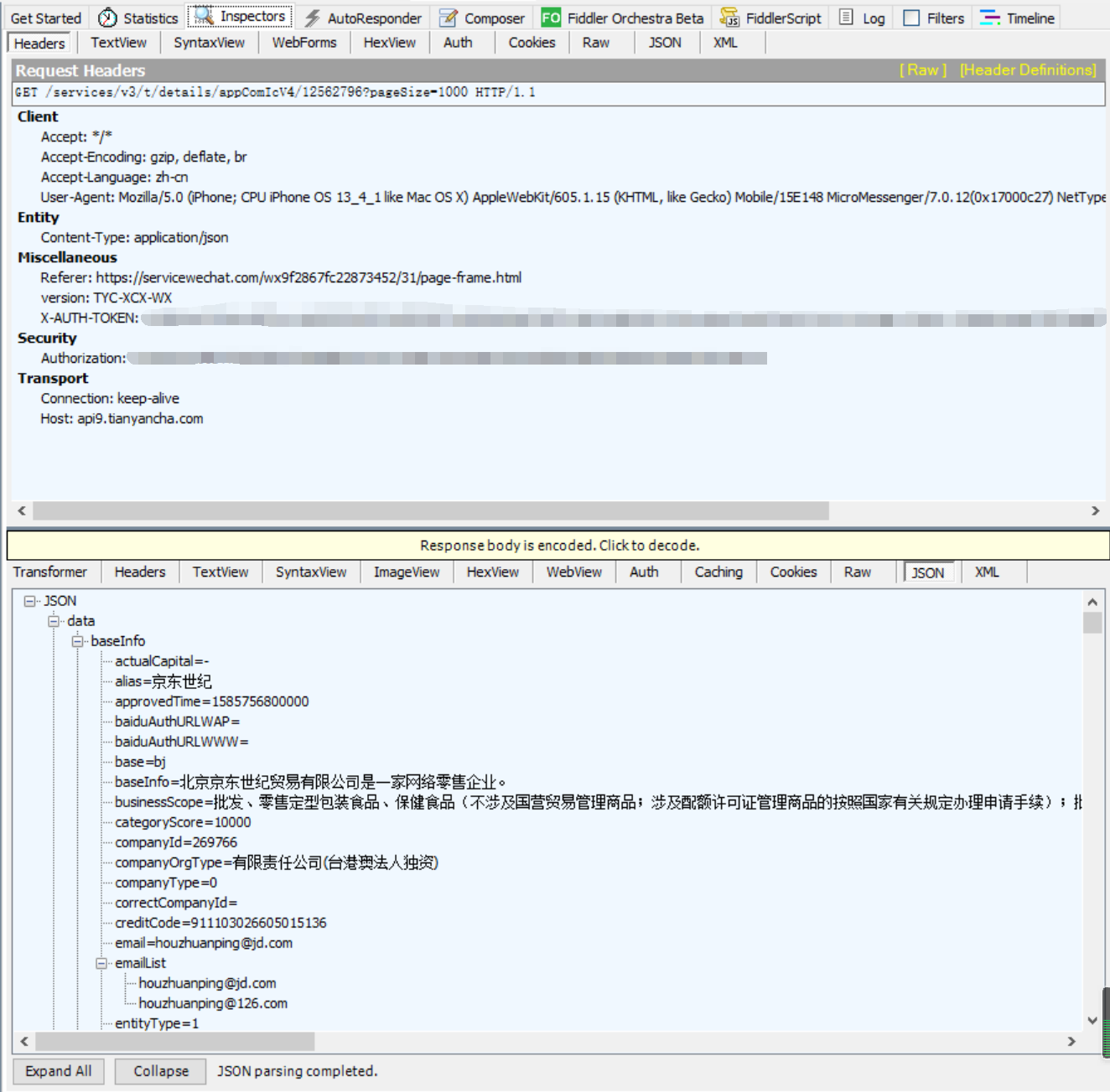
def pares_company_info(company_id):
api_url = f'https://api9.tianyancha.com/services/v3/t/details/appComIcV4/{company_id}?pageSize=1000'
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.12(0x17000c27) NetType/WIFI Language/zh_CN",
"Host": "api9.tianyancha.com",
"Content-Type": "application/json",
"X-AUTH-TOKEN": "",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Accept": "*/*",
"version": "TYC-XCX-WX",
"Referer": "https://servicewechat.com/wx9f2867fc22873452/31/page-frame.html",
"Authorization": "",
"Accept-Language": "zh-cn"
}
json_str = requests.get(api_url, headers=headers, verify=False).json()
item = json_str.get('data')['baseInfo']
try:
name = item.get('name')
legalPersonName = item.get('legalPersonName')
regStatus = item.get('regStatus')
regCapital = item.get('regCapital')
regLocation = item.get('regLocation')
companyOrgType = item.get('companyOrgType', ' ')
businessScope = item.get('businessScope', ' ')
company_info = {
"name": name, "legalPersonName": legalPersonName, "regStatus": regStatus,
"regCapital": regCapital, "regLocation": regLocation, "companyOrgType": companyOrgType,
"businessScope": businessScope
}
print(company_info)
save_to_csv(filename, company_info)
except:
with open('error_id.txt', 'a') as f:
f.write(company_id + '\n')
def save_to_csv(filename, company_info):
with open(filename, 'a', encoding='utf-8', newline='') as f:
fieldnames = ["name", "legalPersonName", "regStatus", "regCapital",
"regLocation", "companyOrgType", "businessScope"]
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerow(company_info)
if __name__ == "__main__":
filename = 'company_info.csv'
with open(filename, 'a', encoding='utf-8', newline='') as f:
fieldnames = ["name", "legalPersonName", "regStatus", "regCapital",
"regLocation", "companyOrgType", "businessScope"]
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
base_url = 'https://m.tianyancha.com/top/companies/p{}'
for page in range(1, 11):
print(f'正在爬取第{page}页。。。')
url = base_url.format(page)
get_company_id(url)
time.sleep(random.uniform(15, 20))
|