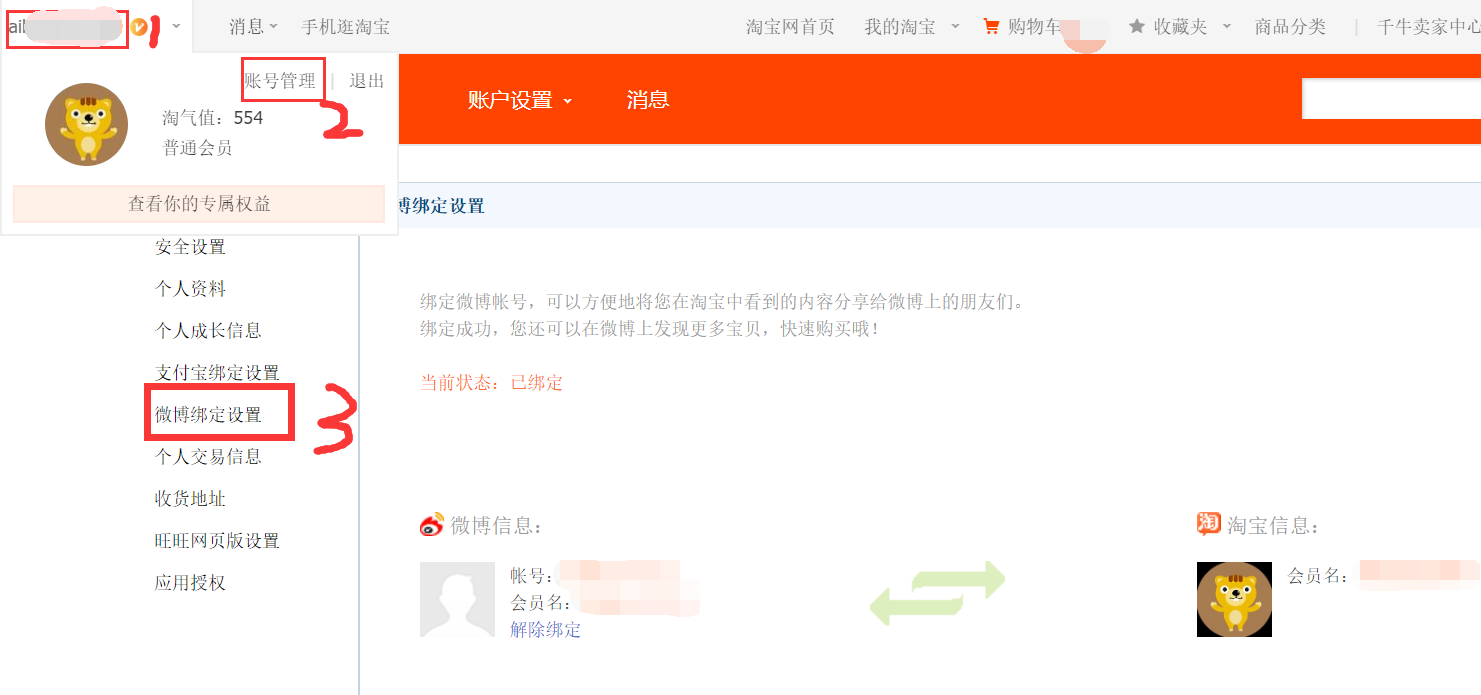
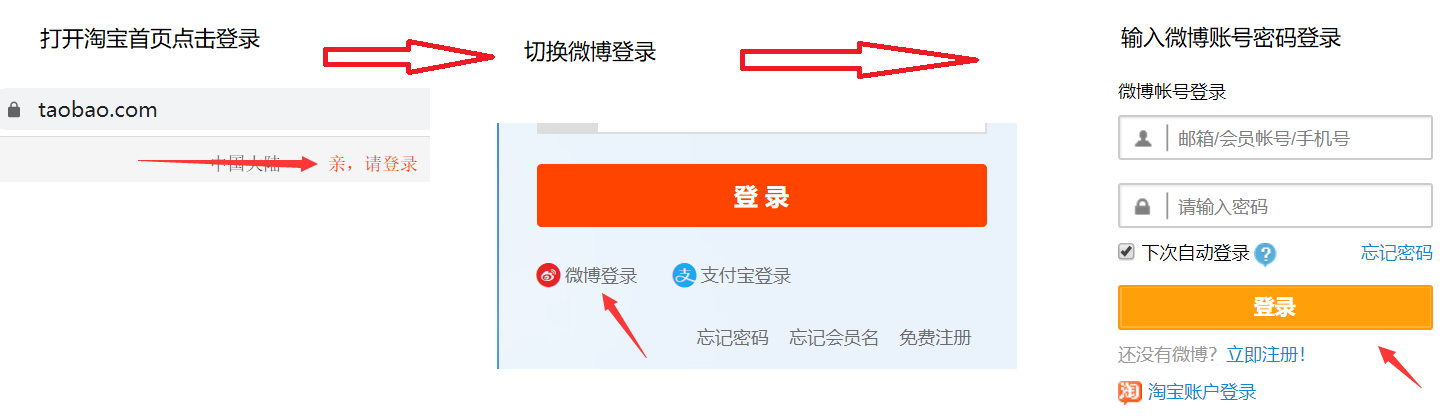
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| import time
import pymongo
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class Taobao:
def __init__(self, trade_name):
self.data = list()
self.isEND = False
self.trade_name = trade_name
self.url = 'https://login.taobao.com/member/login.jhtml'
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.browser = webdriver.Chrome(options=options)
self.wait = WebDriverWait(self.browser, 10)
client = pymongo.MongoClient('localhost')
db = client['taobao']
self.collection = db[self.trade_name]
def login(self, weibo_username, weibo_password):
"""
使用微博登录,避免验证
:param weibo_username: 微博用户名
:param weibo_password: 微博密码
:return:
"""
self.browser.get(self.url)
self.wait.until(EC.presence_of_element_located((By.PARTIAL_LINK_TEXT, '微博登录'))).click()
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.username > .W_input'))).send_keys(weibo_username)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.password > .W_input'))).send_keys(weibo_password)
self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@class="btn_tip"]/a/span'))).click()
taobao_user = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'div.site-nav-user > a.site-nav-login-info-nick')))
print(taobao_user.text)
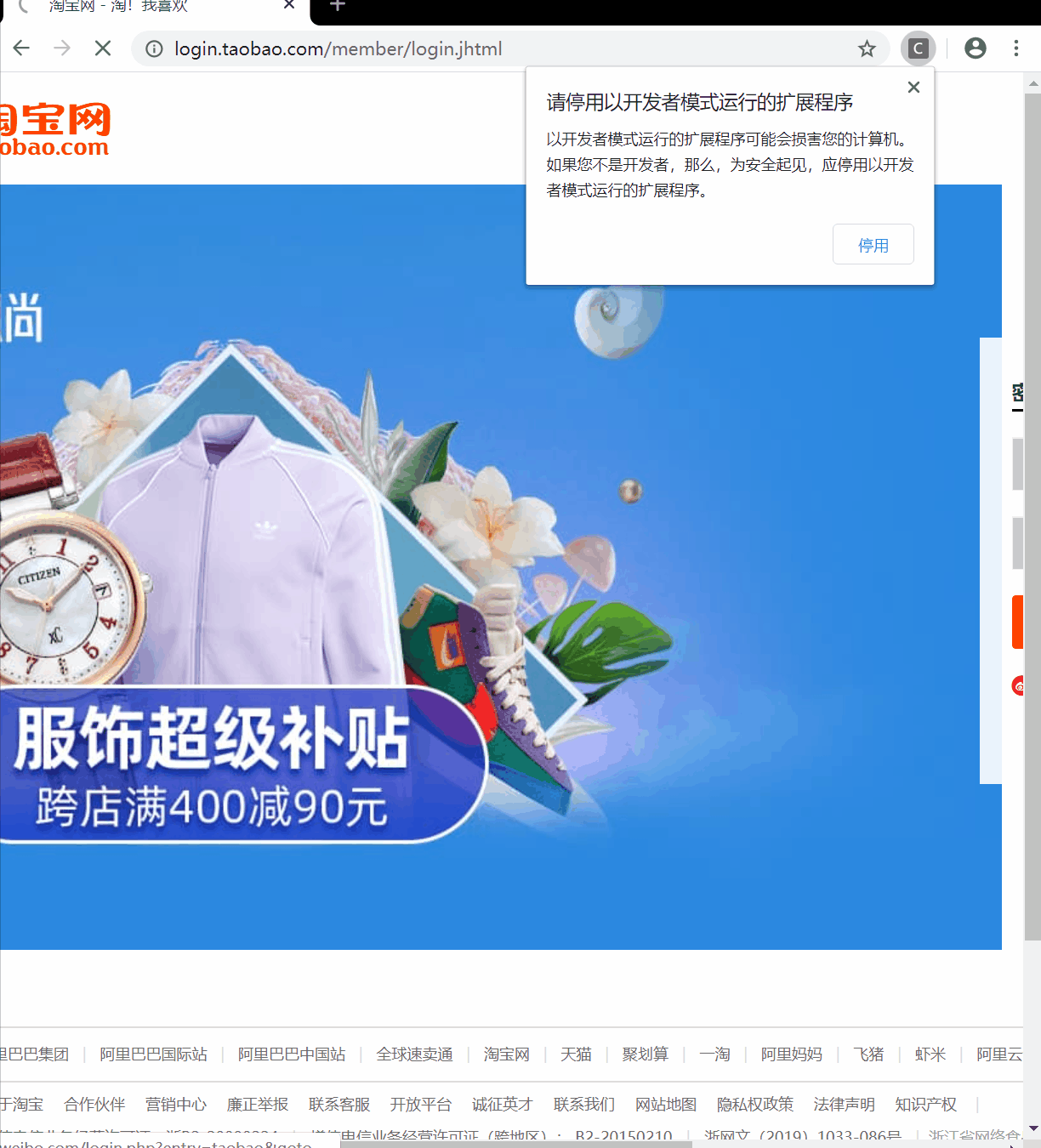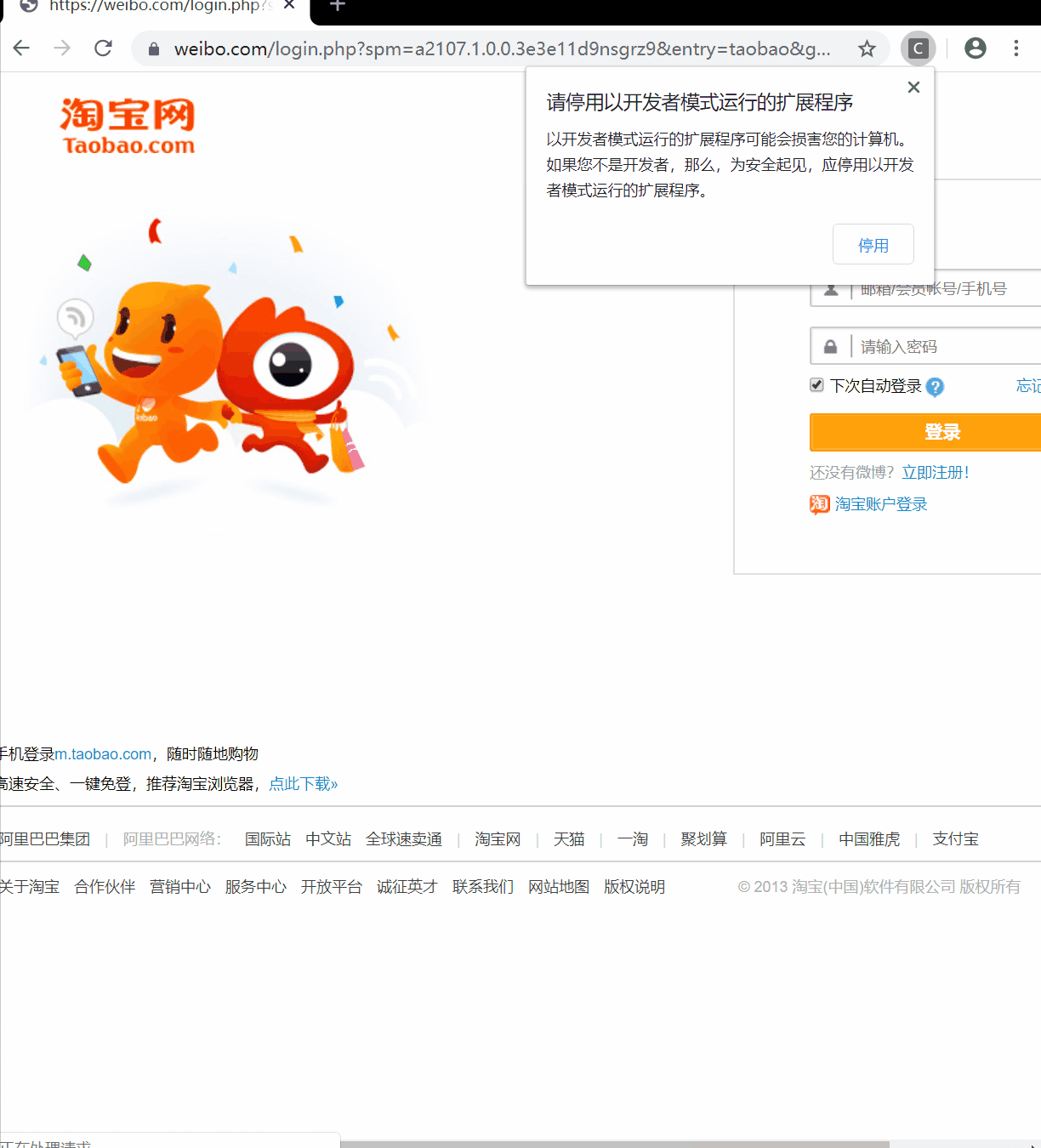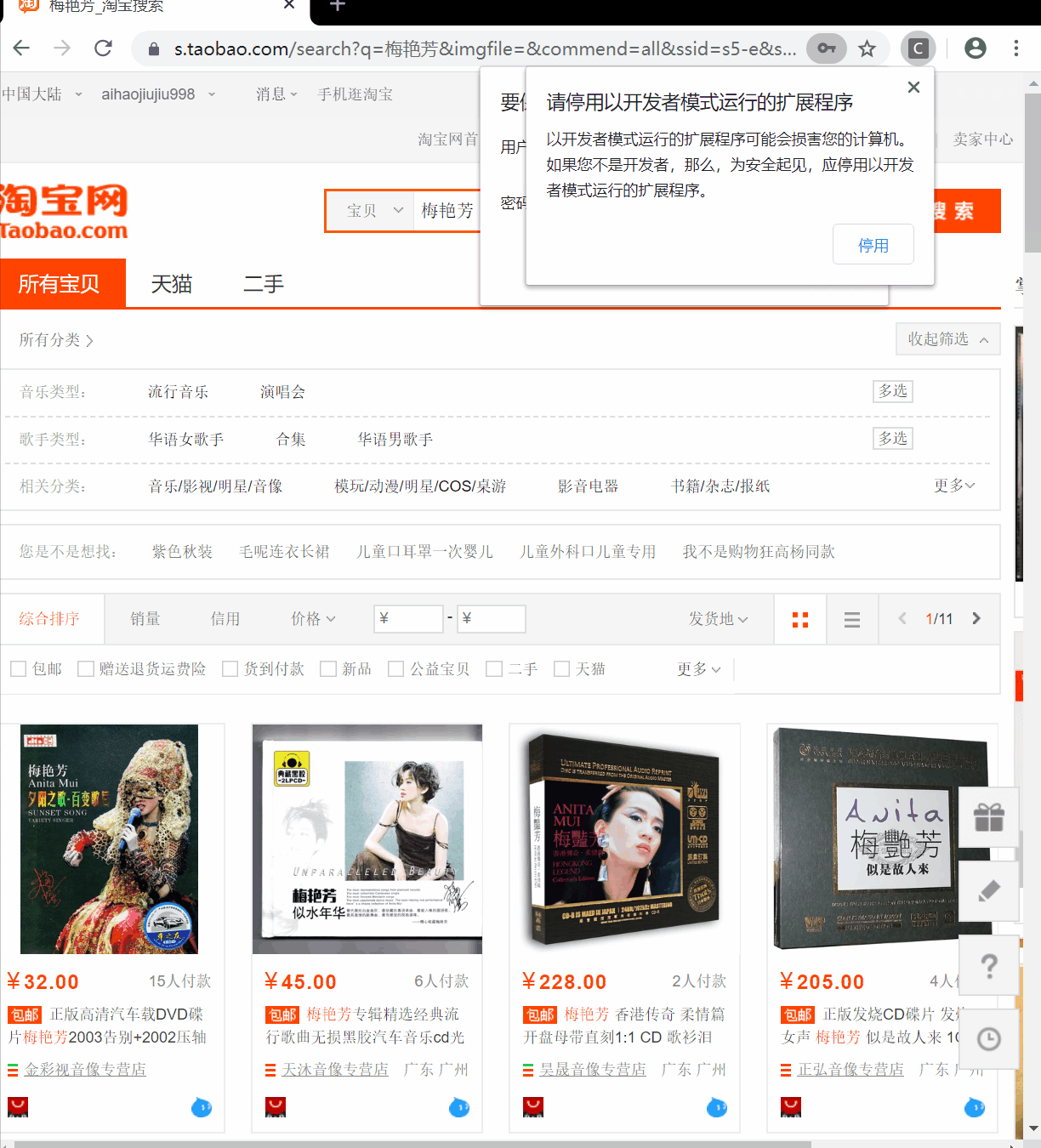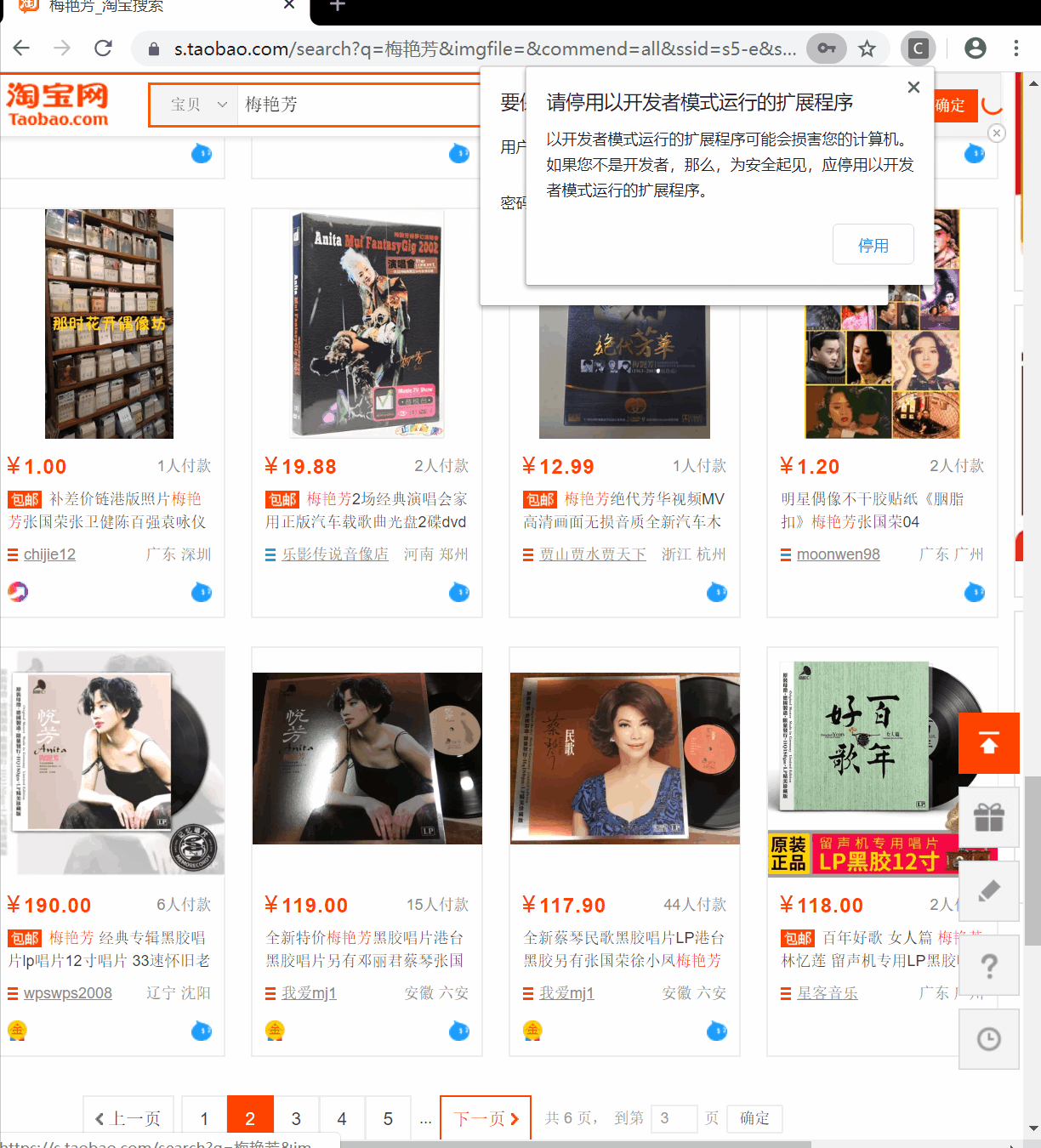
def search(self, kw):
"""
:param kw: 搜索关键字
:return:
"""
self.wait.until(EC.presence_of_element_located((By.ID, 'q'))).send_keys(kw)
self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.search-button > button.btn-search.tb-bg'))).click()
def next_page(self, page=None):
try:
if not page:
all_page_num = int(self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'div.total'))).get_attribute("innerHTML").split()[1])
else:
all_page_num = page
activate_page_num = int(self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'li.item.active > span.num'))).get_attribute("innerHTML"))
if activate_page_num < all_page_num:
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'li.item.next a.J_Ajax.num.icon-tag'))).click()
else:
self.isEND = True
except:
time.sleep(2)
self.next_page()
def parse(self):
time.sleep(3)
try:
doc = pq(self.browser.page_source)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
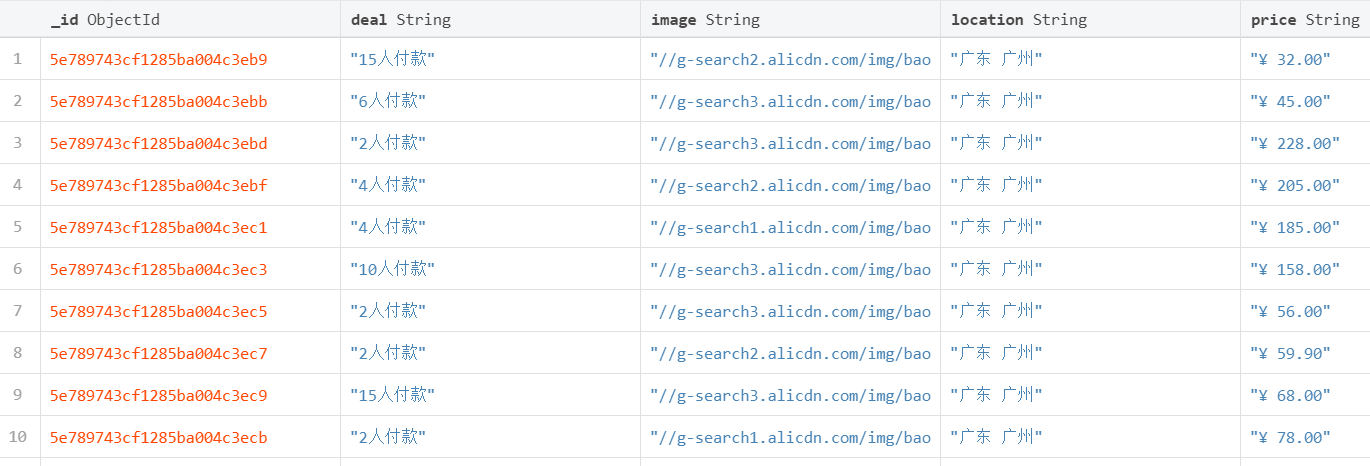
product = [{
"image": item.find('.pic .img').attr('data-src'),
"price": item.find('.price').text(),
"deal": item.find('.deal-cnt').text(),
"title": item.find('.title').text(),
"shop": item.find('.shop').text(),
"location": item.find('.location').text(),
}]
self.data.extend(product)
self.next_page()
except:
time.sleep(3)
self.parse()
def save_to_mongo(self):
try:
for item in self.data:
if self.collection.update_one(item, {"$setOnInsert": item}, True):
pass
print("储存到MongoDB成功")
except Exception:
print("储存到MongoDB失败")
def main(self):
self.search(self.trade_name)
while not self.isEND:
self.parse()
self.save_to_mongo()
if __name__ == "__main__":
weibo_username = "XXXX"
weibo_password = "XXXX"
trade_name = '梅艳芳'
taobao = Taobao(trade_name)
taobao.login(weibo_username, weibo_password)
taobao.main()
|