Do you take anyone else’s word about what is right and wrong. ——《21座桥》
不要人云亦云。
语法
1
| open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
|
1
2
3
4
5
6
7
| file : 包含了目标名称的字符串值。
mode : 决定了打开文件的模式。默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。
如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。
如果取负值,寄存区的缓冲大小则为系统默认。
encoding: 对文件规定打开的编码
newline = "":读取文件真正的换行符,在window里面为"\r\n",Linux和Python里面为"\n"
|
打开方式
| 模式 |
描述 |
| r |
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb |
以二进制只读方式打开一个文件。文件指针将会放在文件的开头。 |
| r+ |
以读写方式打开一个文件。文件指针将会放在文件的开头。 |
| rb+ |
以二进制读写方式打开一个文件。文件指针将会放在文件的开头。 |
| w |
以写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。 |
| wb |
以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。 |
| w+ |
以读写方式打开一个文件。如果该文件已存在,则会将其覆盖。如果该文件不存在,则创建新文件。 |
| wb+ |
以二进制读写格式打开一个文件。如果该文件已存在,则会将其覆盖。如果该文件不存在,则创建新文件。 |
| a |
以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件进行写入。 |
| ab |
以二进制追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件进行写入。 |
| a+ |
以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,则创建新文件用于读写。 |
| ab+ |
以二进制追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,则创建新文件用于读写。 |
file对象
| 方法 |
描述 |
| file.close() |
关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush() |
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno() |
返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() |
如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.next() |
返回文件下一行。 |
| file.read([size]) |
从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) |
读取整行,包括 “\n” 字符。 |
| file.readlines([sizehint]) |
读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| file.seek(offset[, whence]) |
设置文件当前位置 |
| file.tell() |
返回文件当前位置。 |
| file.truncate([size]) |
截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| file.write(str) |
将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) |
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
TXT文本储存
将字符串写入TXT文件
1
2
3
4
| str1 = "Do you take anyone else's word about what is right and wrong.\n"
file = open('txtfile.txt', 'w')
file.write(str1)
file.close()
|
简化写法
使用with as语法。在with控制块结束时,文件会自动关闭,也就不用调用close()方法了。
1
2
| with open('txtfile.txt', 'a+') as f:
f.write(str1)
|
将中文字符串写入TXT文件
1
2
| with open('txtfile.txt', 'a+') as f:
f.write('Python数据储存\n')
|
然后就发现它乱码了。

解决方法:用utf-8的格式打开文件
1
2
| with open('txtfile.txt', 'a+', encoding="utf-8") as f:
f.write('Python数据储存\n')
|
输出:

同理:如果需要读取含有中文的文件的时候,也需要指定utf-8的格式来打开
读取TXT文件
1
2
| with open('txtfile.txt', 'r', encoding='utf-8') as f:
print(f.read())
|
输出:

其他用法请查看前面file对象的相关方法以及说明
JSON文件储存
Python为我们提供了简单易用的JSON库实现文件的读写操作,我们可以调用JSON库的loads()方法将JSON文本字符串转为JSON对象,可以通过loads()方法将JSON对象转为文本字符串。
读取JSON字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import json
str1 = '''[{
"name": "SQL必知必会",
"publication": "2009-01"
}, {
"name": "C++ Primer Plus",
"publication": "2012-07"
}]'''
print(type(str1))
data = json.loads(str1)
print(data)
print(type(data))
|
输出:

这里使用loads()方法将字符串转换为JSON对象。由于最外层是中括号,所以最终数据类型是列表。这样我们就可以用索引来获取对应的内容了。例如:获取第一个元素里的name属性:
1
2
| print(data[0]['name'])
print(data[0].get('name'))
|
得到的结果都是:

需要注意的是,JSON数据需要用双引号来包围,不能使用单引号,否则的话,例如:
1
2
3
4
5
6
7
8
| str1 = '''[{
'name': 'SQL必知必会',
'publication": "2009-01'
}, {
'name': 'C++ Primer Plus',
'publication': '2012-07'
}]'''
data = json.loads(str1)
|
运行结果如下:

这里会出现JSON解析错误,原因就是数据使用单引号包围。
将JSON对象写入文本
1
2
3
4
5
6
7
8
9
10
11
| import json
data = [{
"name": "SQL必知必会",
"publication": "2009-01"
}, {
"name": "C++ Primer Plus",
"publication": "2012-07"
}]
with open('data.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False))
|
利用dumps()方法我们可以将JSON对象转为字符串,然后再调用write()方法写入文本。如图:

因为JSON对象含有中文字符,所以需要ensure_ascii=False保证不会以ASCII编码,以确保中文的正常转换。当然,如果JSON对象中不含有有中文,你可以不必指定这个参数。下面是错误的例子:
1
2
| with open('data.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(data))
|
输出:

如果你想保存JSON格式,可以添加indent参数,代表缩进字符个数。示例如下:
1
2
| with open('data.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False, indent=4))
|
结果如下:

这样得到的内容会自动带缩进,格式会更加清晰。
从JSON文本中读取内容
1
2
3
4
5
6
| import json
with open('data.json', 'r', encoding='utf-8') as f:
str1 = f.read()
data = json.loads(str1)
print(data)
|
因为文本中含有中文所以,需要指定编码,否则会乱码。运行结果如下:
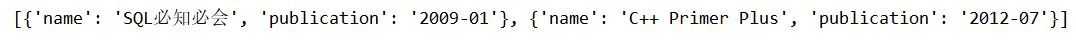
CSV文件储存
写入一行数据
1
2
3
4
5
6
7
8
| import csv
with open('data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'name', 'age'])
writer.writerow(['10001', 'Mike', '20'])
writer.writerow(['10002', 'Bob', '23'])
writer.writerow(['10003', 'Jordan', '21'])
|
直接以文本打开如下:

可以看到写入的文本默认是以逗号分割的,每调用一次writerow()方法即可写入一行数据。用Excel打开的结果如图:

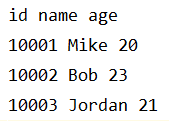
如果想修改列与列之间的分隔符,可以传入delimiter参数。
1
2
3
4
5
6
| with open('data2.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile, delimiter=' ')
writer.writerow(['id', 'name', 'age'])
writer.writerow(['10001', 'Mike', '20'])
writer.writerow(['10002', 'Bob', '23'])
writer.writerow(['10003', 'Jordan', '21'])
|
结果如下:
写入多行数据
调用writerows()方法可以同时写入多行,而此时参数就需要为二维列表。
1
2
3
4
| with open('data3.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'name', 'age'])
writer.writerows([['10001', 'Mike', '20'], ['10002', 'Bob', '23'], ['10003', 'Jordan', '21']])
|
结果和一行一行写是相同。如下:
将字典写入CSV文件
1
2
3
4
5
6
7
| with open('data4.csv', 'w', newline='') as csvfile:
fieldnames = (['id', 'name', 'age'])
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'id': '10001', 'name': 'Mike', 'age': '20'})
writer.writerow({'id': '10002', 'name': 'Bob', 'age': '23'})
writer.writerow({'id': '10003', 'name': 'Jordan', 'age': '21'})
|
结果如下:
如果是想追加写入的话,只需修改文件的打开模式,即open()函数的第二个参数修改为a。
1
2
3
4
| with open('data4.csv', 'a', newline='') as csvfile:
fieldnames = (['id', 'name', 'age'])
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow({'id': '10004', 'name': 'Durant', 'age': '19'})
|
在上面的基础上内容变为:

此外,如果要写入中文内容的话,可能会遇到编码问题,需要指定编码格式。代码改写如下:
1
2
3
4
| with open('data4.csv', 'a', encoding='utf-8', newline='') as csvfile:
fieldnames = (['id', 'name', 'age'])
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow({'id': '10005', 'name': '张伟', 'age': '32'})
|
读取CSV文件
因为文本中含有中文,所以指定了编码格式,否则可能会遇到乱码问题。
1
2
3
4
| with open('data4.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
print(row)
|
运行结果如下:

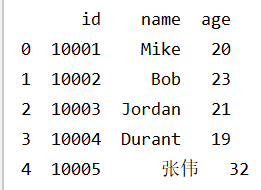
此外,还可以利用pandas的read_csv()方法将数据从CSV中读取出来。
1
2
3
4
| import pandas as pd
df = pd.read_csv('data4.csv')
print(df)
|
运行结果如下: