When one can see no future, all one can do is the next right thing. ——《冰雪奇缘2》 如果看不清未来,就走好当下的路。
抓取目标
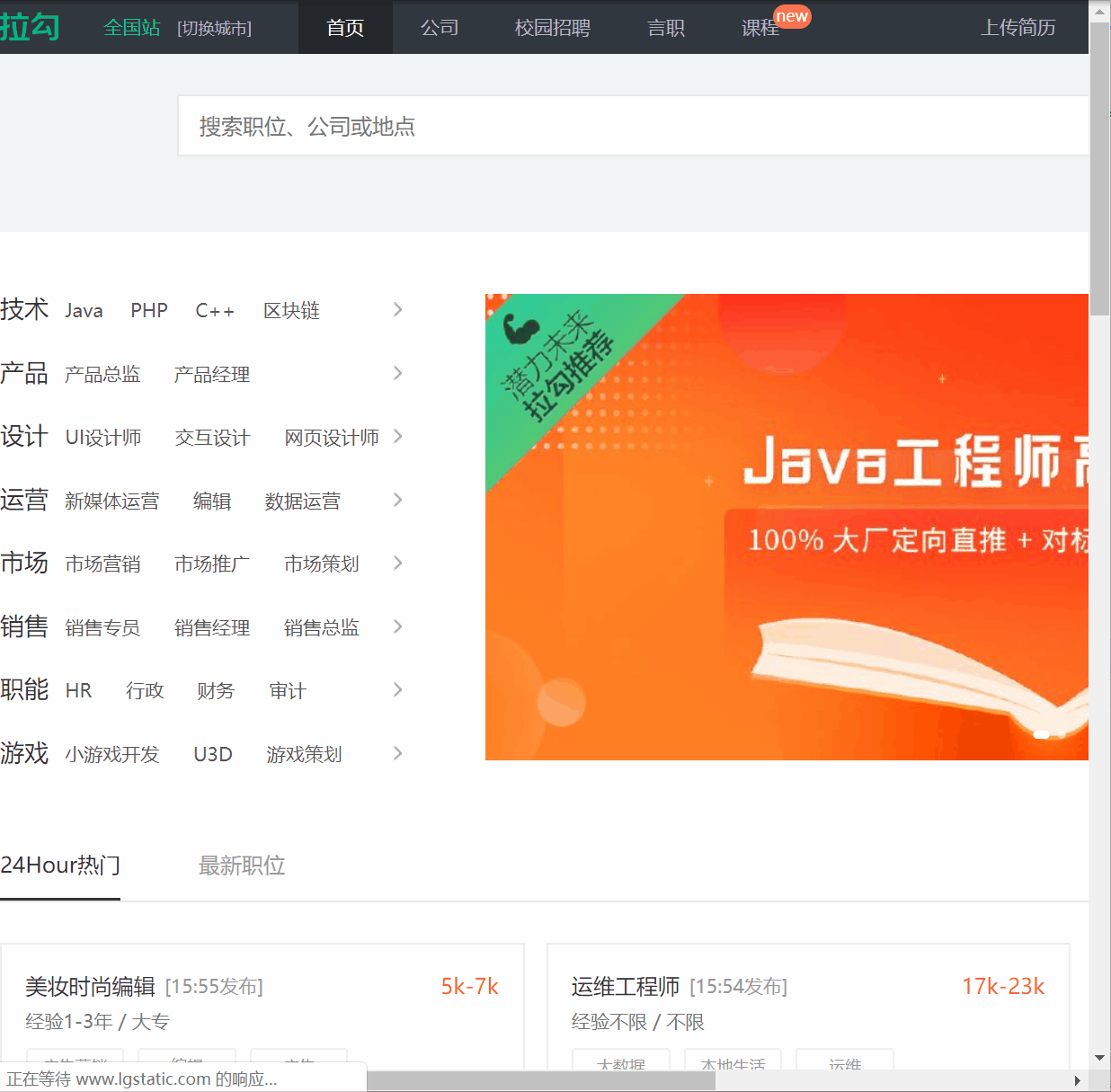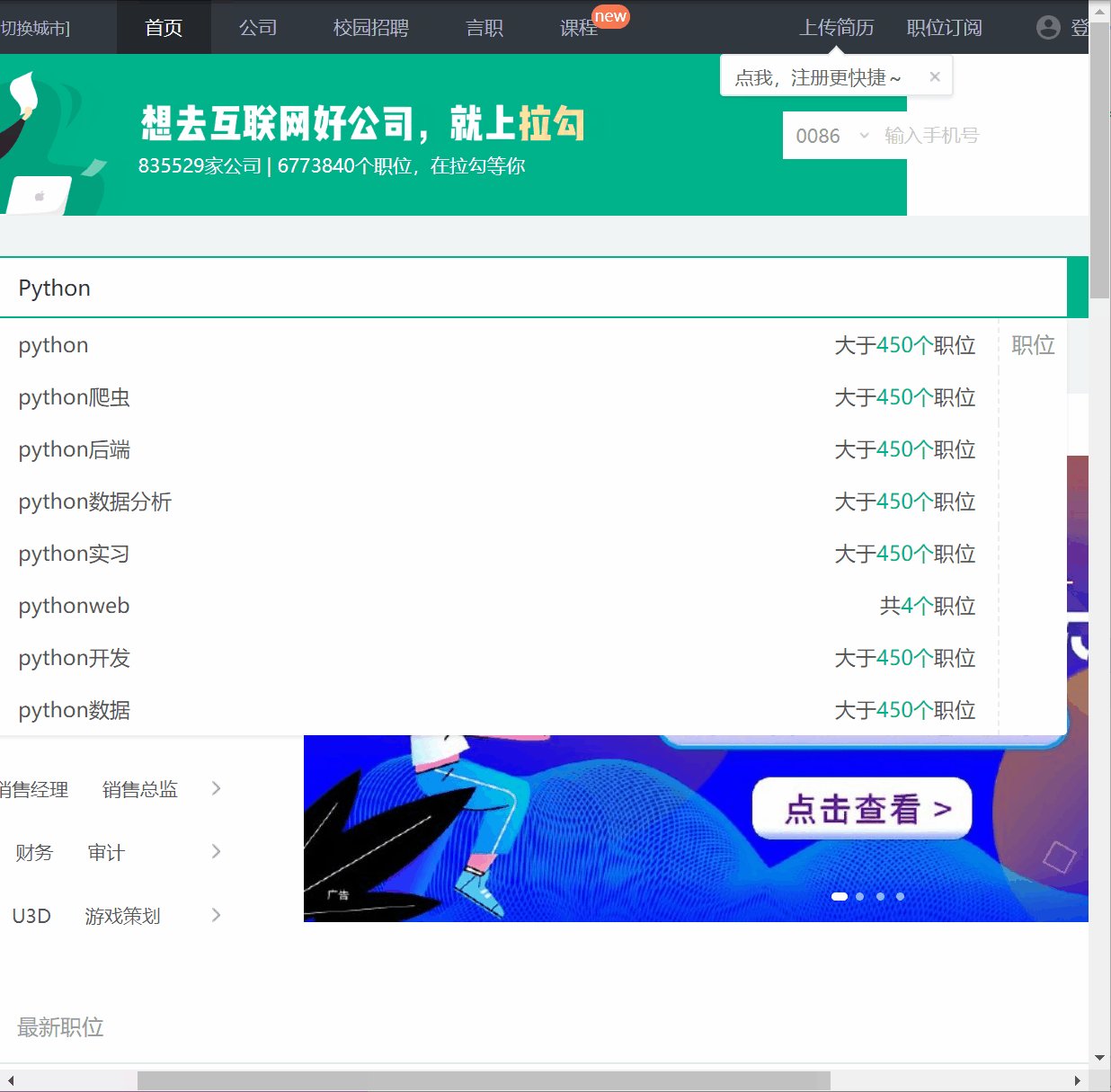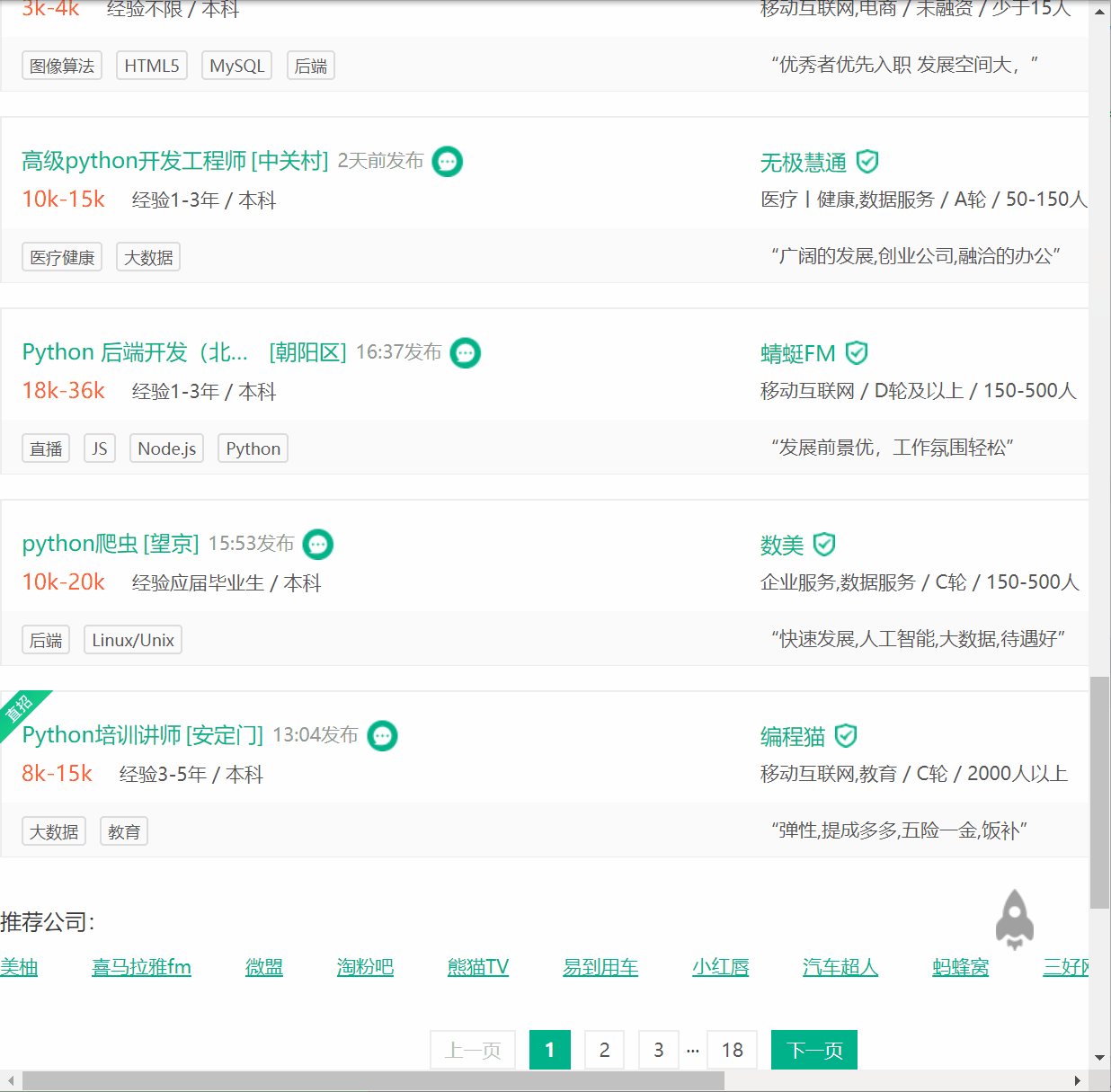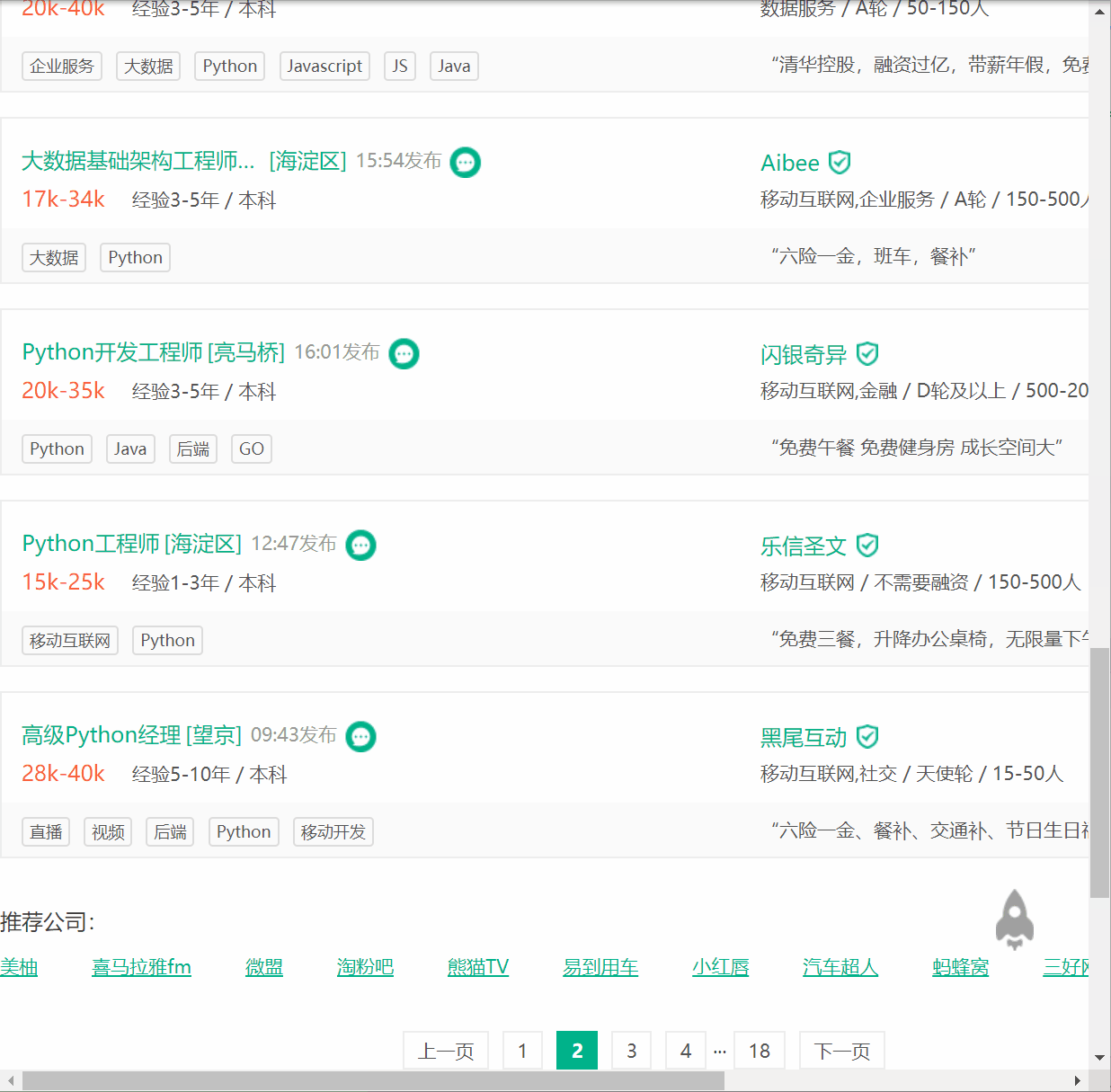
利用Selenium抓取拉钩Python相关职位并用pyquery解析得到Python相关职位的职位名称、所在城市、薪资、需要经验、教育程度以及公司名称,并将其保存到MongoDB。
思路分析
既然准备使用Selenium那我们就全程让他模拟人的行为去进行一些操作。初步思路如下:
站点分析
站点的搜索框以及搜索按钮如下:
初始化代码
首先构造一个WebDriver对象,使用的是浏览器Chrome,然后模拟人的行为:在搜索框中输入想要搜索的职位,然后点击搜索。初始化MongoDB,首先创建了一个MongoDB连接对象,然后指定了Collection的名称。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import timeimport pymongofrom selenium import webdriverfrom pyquery import PyQuery as pqfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECclass LagouSpider : def __init__ (self ): self.data = list () self.isEnd = False self.browser = webdriver.Chrome() self.wait = WebDriverWait(self.browser, 10 ) self.browser.get('https://www.lagou.com/' ) input_search = self.browser.find_element_by_id('search_input' ) input_search.send_keys('Python' ) time.sleep(1 ) button = self.browser.find_element_by_class_name('search_button' ) button.click() client = pymongo.MongoClient('localhost' ) db = client.lagou self.collection = db.Python
解析职位列表
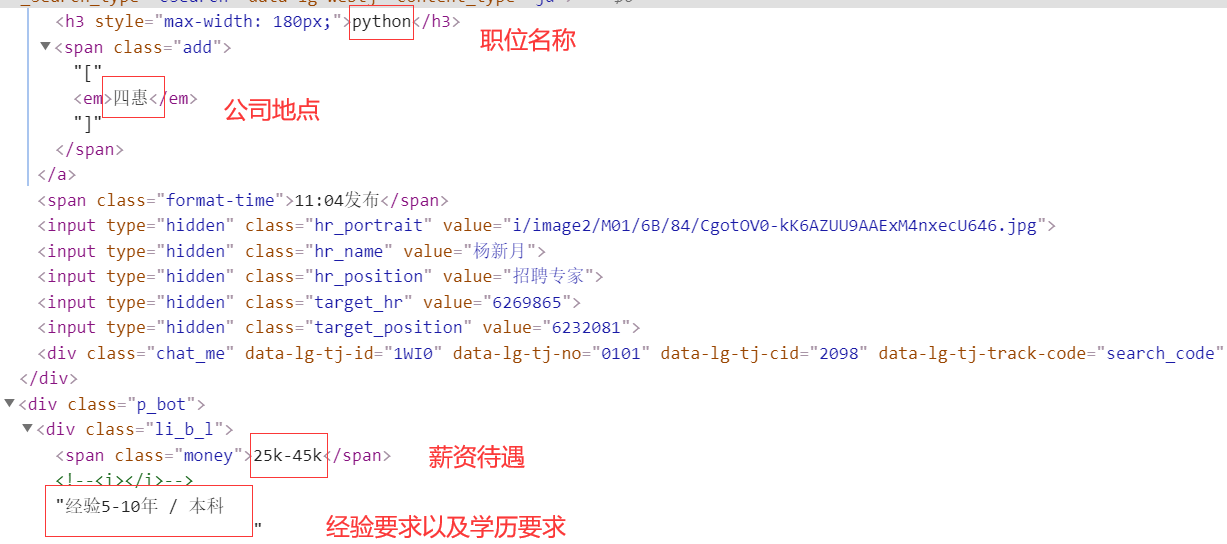
我们直接获取页面源代码,然后构造PyQuery解析对象,接着提取了职位列表,此时使用的CSS选择器是#s_position_list .item_con_list .con_list_item,它会匹配整个页面的每一个职位。因为它匹配的结果是多个,所以我们对它进行了以此遍历,用for循环将每一个结果分别进行解析,每一次循环把它赋值为item变量,每一个item变量都是一个PyQuery对象,然后调用它的find()方法,传入CSS选择器,就可以得到每一个职位的特定内容了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def parse_page (self ): try : doc = pq(self.browser.page_source) items = doc('#s_position_list .item_con_list .con_list_item' ).items() for item in items: money_experience_educational = item.find('.position .p_bot .li_b_l' ).text().split(' ' ) product = [{ "position" : item.find('.p_top .position_link h3' ).text(), "city" : item.find('.position .p_top .add em' ).text(), "money" : money_experience_educational[0 ], "experience" : money_experience_educational[1 ], "educational" : money_experience_educational[3 ], "company" : item.find('.company .company_name a' ).text(), }] self.data.extend(product) except : time.sleep(3 ) self.parse_page()
翻页操作
首先判断是不是最后一页,不是的话才模拟点击下一页,否则的改变Flag。
1 2 3 4 5 6 7 def turn_page (self ): if pq(self.browser.page_source)('.pager_container span:last-child' ).attr('class' ) != 'pager_next pager_next_disabled' : pager_next = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'pager_next' ))) pager_next.click() time.sleep(2 ) else : self.isEnd = True
保存到MongoDB
因为在之前初始化了MongoDB,所以这里直接将数据插入到MongoDB。update_one()方法:更新或插入一条数据。这里使用update_one()方法一条一条插入是为了去重数据。
1 2 3 4 5 6 7 8 def save_to_mongo (self ): try : for item in self.data: if self.collection.update_one(item, {"$setOnInsert" : item}, True ): pass print ('储存到MongoDB成功' ) except Exception: print ('储存到MongoDB失败' )
定义爬取函数
这里提取了每一页的当前页码,使我们可以很方便的观察爬取进度。
1 2 3 4 5 6 7 8 def crawl (self ): while not self.isEnd: page = self.browser.find_element_by_class_name('pager_is_current' ).text print ('正在爬取第 ' + page + ' 页 ...' ) self.parse_page() self.turn_page() self.save_to_mongo() print ('爬取结束' )
试运行
此时的全部代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import timeimport pymongofrom selenium import webdriverfrom pyquery import PyQuery as pqfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECclass LagouSpider : def __init__ (self ): self.data = list () self.isEnd = False self.browser = webdriver.Chrome() self.wait = WebDriverWait(self.browser, 10 ) self.browser.get('https://www.lagou.com/' ) input_search = self.browser.find_element_by_id('search_input' ) input_search.send_keys('Python' ) time.sleep(1 ) button = self.browser.find_element_by_class_name('search_button' ) button.click() client = pymongo.MongoClient('localhost' ) db = client.lagou self.collection = db.Python def parse_page (self ): try : doc = pq(self.browser.page_source) items = doc('#s_position_list .item_con_list .con_list_item' ).items() for item in items: money_experience_educational = item.find('.position .p_bot .li_b_l' ).text().split(' ' ) product = [{ "position" : item.find('.p_top .position_link h3' ).text(), "city" : item.find('.position .p_top .add em' ).text(), "money" : money_experience_educational[0 ], "experience" : money_experience_educational[1 ], "educational" : money_experience_educational[3 ], "company" : item.find('.company .company_name a' ).text(), }] self.data.extend(product) except : time.sleep(3 ) self.parse_page() def turn_page (self ): if pq(self.browser.page_source)('.pager_container span:last-child' ).attr('class' ) != 'pager_next pager_next_disabled' : pager_next = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'pager_next' ))) pager_next.click() time.sleep(2 ) else : self.isEnd = True def save_to_mongo (self ): try : for item in self.data: if self.collection.update_one(item, {"$setOnInsert" : item}, True ): pass print ('储存到MongoDB成功' ) except Exception: print ('储存到MongoDB失败' ) def crawl (self ): while not self.isEnd: page = self.browser.find_element_by_class_name('pager_is_current' ).text print ('正在爬取第 ' + page + ' 页 ...' ) self.parse_page() self.turn_page() self.save_to_mongo() print ('爬取结束' ) if __name__ == '__main__' : obj = LagouSpider() obj.crawl()
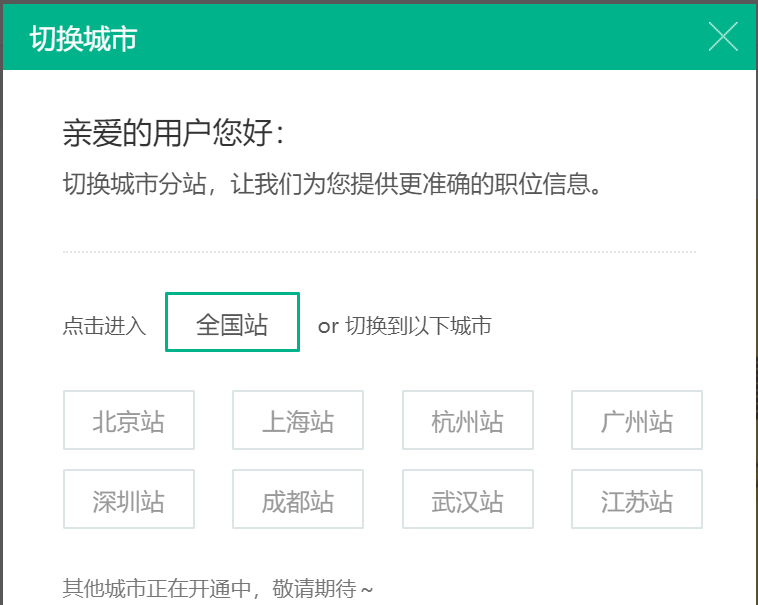
我们运行一下代码发现出现了:selenium.common.exceptions.ElementNotInteractableException: Message: element not interactable 错误。我们再看一看浏览器现在是什么情况,发现浏览器出现了弹窗,如下图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class LagouSpider : def __init__ (self ): self.data = list () self.isEnd = False self.browser = webdriver.Chrome() self.wait = WebDriverWait(self.browser, 10 ) self.browser.get('https://www.lagou.com/' ) index_tab = self.browser.find_element_by_xpath('//*[@id="changeCityBox"]/ul/li[1]/a' ) index_tab.click() input_search = self.browser.find_element_by_id('search_input' ) input_search.send_keys('Python' ) time.sleep(1 ) button = self.browser.find_element_by_class_name('search_button' ) button.click() client = pymongo.MongoClient('localhost' ) db = client.lagou self.collection = db.Python
我们再运行一下试试。然后顺利点击首页弹窗,顺利在输入框输入职位,顺利点击搜索,然后进入到职位详情页,突然就蹦出来这么一个玩意:
1 2 3 4 5 6 7 8 9 def body_btn (self ): try : body_btn = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.body-btn' ))) if body_btn: body_btn.click() time.sleep(3 ) except : pass
经过多次试验,当弹窗的class的属性为 body-container 的时候,弹窗是不会展示在页面的;当弹窗的class的属性为 body-container showData 的时候,弹窗才会展示在页面。修改抓取函数代码,具体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def crawl (self ): while not self.isEnd: page = self.browser.find_element_by_class_name('pager_is_current' ).text print ('正在爬取第 ' + page + ' 页 ...' ) try : showData = self.browser.find_element_by_css_selector('[class="body-container showData"]' ) except : showData = False if showData: self.body_btn() self.parse_page() self.turn_page() self.save_to_mongo() print ('爬取结束' )
整合所有代码
经过一系列的弹窗,最终代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 import timeimport pymongofrom selenium import webdriverfrom pyquery import PyQuery as pqfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECclass LagouSpider : def __init__ (self ): self.data = list () self.isEnd = False self.browser = webdriver.Chrome() self.wait = WebDriverWait(self.browser, 10 ) self.browser.get('https://www.lagou.com/' ) index_tab = self.browser.find_element_by_xpath('//*[@id="changeCityBox"]/ul/li[1]/a' ) index_tab.click() input_search = self.browser.find_element_by_id('search_input' ) input_search.send_keys('Python' ) time.sleep(1 ) button = self.browser.find_element_by_class_name('search_button' ) button.click() client = pymongo.MongoClient('localhost' ) db = client.lagou self.collection = db.Python def parse_page (self ): try : doc = pq(self.browser.page_source) items = doc('#s_position_list .item_con_list .con_list_item' ).items() for item in items: money_experience_educational = item.find('.position .p_bot .li_b_l' ).text().split(' ' ) product = [{ "position" : item.find('.p_top .position_link h3' ).text(), "city" : item.find('.position .p_top .add em' ).text(), "money" : money_experience_educational[0 ], "experience" : money_experience_educational[1 ], "educational" : money_experience_educational[3 ], "company" : item.find('.company .company_name a' ).text(), }] self.data.extend(product) except : time.sleep(3 ) self.parse_page() def turn_page (self ): if pq(self.browser.page_source)('.pager_container span:last-child' ).attr('class' ) != 'pager_next pager_next_disabled' : pager_next = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'pager_next' ))) pager_next.click() time.sleep(2 ) else : self.isEnd = True def body_btn (self ): try : body_btn = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.body-btn' ))) if body_btn: body_btn.click() time.sleep(3 ) except : pass def save_to_mongo (self ): try : for item in self.data: if self.collection.update_one(item, {"$setOnInsert" : item}, True ): pass print ('储存到MongoDB成功' ) except Exception: print ('储存到MongoDB失败' ) def crawl (self ): while not self.isEnd: page = self.browser.find_element_by_class_name('pager_is_current' ).text print ('正在爬取第 ' + page + ' 页 ...' ) try : showData = self.browser.find_element_by_css_selector('[class="body-container showData"]' ) except : showData = False if showData: self.body_btn() self.parse_page() self.turn_page() self.browser.close() self.save_to_mongo() print ('爬取结束' ) if __name__ == '__main__' : obj = LagouSpider() obj.crawl()
效果展示
爬取效果
数据展示
写在最后
你也可以使用Headless模式,也就是无界面模式,这样爬取的时候就不会弹出浏览器了。具体代码如下:
将初始化时的:
1 self.browser = webdriver.Chrome()
修改为:
1 2 3 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--headless' ) self.browser = webdriver.Chrome(chrome_options=chrome_options)