Scrapy
什么是 Scrapy
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
截止2020年11月16日,Scrapy最新版本为2.4,Python版本最低要求3.6+,适用于Linux,Windows,macOS,BSD
Scrapy 官方站点
github地址:https://github.com/scrapy/scrapy
官方社区:https://scrapy.org/
官方文档:https://docs.scrapy.org/en/latest/
安装 Scrapy
1 | pip install scrapy |
你也可以指定源,一般这样会快很多。
1 | pip install scrapy -i https://pypi.douban.com/simple |
如果你的scrapy是很早之前安装的,你也可以使用下面的命令进行升级安装。
1 | pip install scrapy -i --upgrade https://pypi.douban.com/simple |
我在使用上面的命令进行更新时出现了以下错误:

意思是:gerapy 0.9.2 版本要求 pymysql 的版本为 0.7.10,但是您的 pymysql 版本为 0.10.1,这是不兼容的。不过在上图的最后一行中,我们可以了解到 scrapy 是更新成功的。
使用下面的命令查看scrapy 现在的版本。确定scrapy是更新成功了。既然安装成功就暂时先不管这些小问题了。
1 | scrapy --version |

使用 pip install scrapy 安装,极可能会遇到 Twisted 安装报错以及其他包版本的错误。
关于 Twisted 可以在这个网站下载:https://pypi.org/project/Twisted/#files
在下载之前一定要先确定你机器上的Python版本,在cmd中输入python即可,如下图:

可以看出我的python版本是3.7,机器是64位机器,那么我就可以下载下图所示版本:
下载完成之后 使用 win + R 输入cmd 打开命令窗口,并输入 pip install 然后将你下载好的Twisted文件拖进命令窗口,然后回车即可安装。
安装完 Twisted 再次执行 pip install scrapy 命令进行安装,如果遇到其他包版本问题,按照错误提示安装指定版本的包即可。
当然我最推荐的安装方式是:先安装anaconda,然后安装scrapy,这样可以避免很多错误以节约时间。关于anaconda的下载可以到清华大学开源软件镜像站,关于镜像源的更换可以看百度经验 - anaconda清华源更换这篇文章。
在清华源镜像站中 Anaconda3-2020.02-Windows-x86_64.exe 是最新的支持python3.7的版本,Anaconda3-2020.07-Windows-x86_64.exe是最新的支持python3.8的版本,关于其他版本可自行安装测试。
Scrapy架构
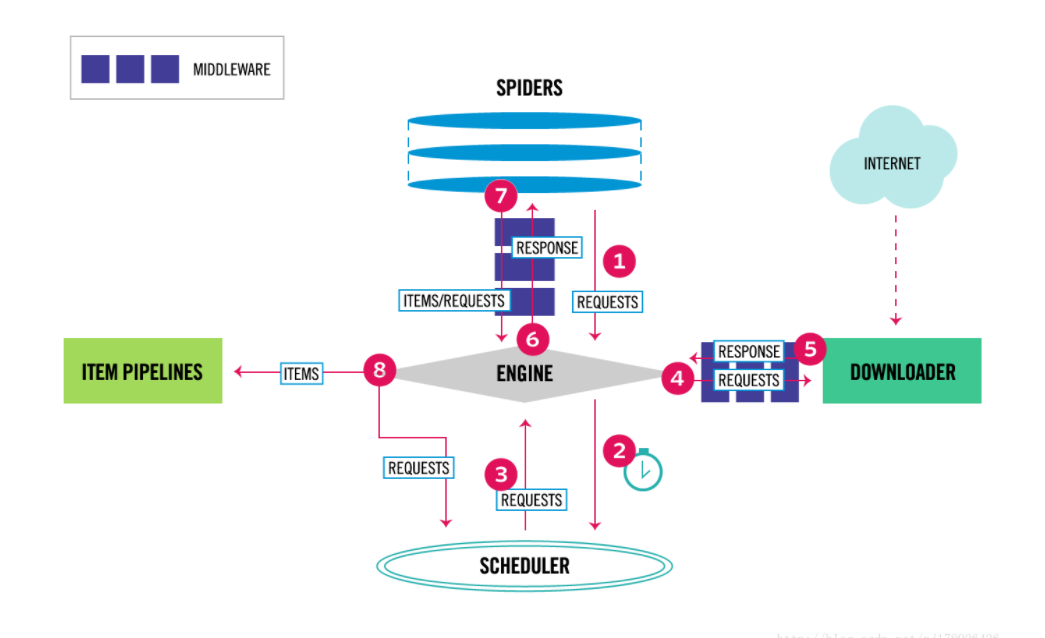
Scrapy 组件
1、Scrapy Engine (引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
2、Scheduler (调度器):
负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
3、Downloader (下载器):
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
4、Spider (爬虫):
负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
5、Item Pipeline (管道):
负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
6、Downloader Middlewares (下载中间件):
介于Scrapy引擎和下载器之间的中间件,可以自定义扩展下载功能的组件。
7、Spider Middlewares (爬虫中间件):
介于Scrapy引擎和爬虫之间的中间件,可以自定义扩展操作引擎和爬虫中间通信的功能组件。
8、Scheduler Middlewares(调度中间件):
介于Scrapy引擎和调度之间的中间件,可以自定义扩展操作引擎和调度器中间通信的功能组件。
Scrapy 运行流程
1、Spider:Engine,Engine 起来干活了!Spider 将 第一个 requests 发送给 Engine (引擎)
2、Engine:知道了! Engine 对 requests 不做任何的处理就发送给 Scheduler (调度器)
3、Scheduler:看了一眼这个 requests,Scheduler 将 requests 发送给 Engine (引擎) ,并告诉引擎:你把它交给 Downloader (下载器)
4、Engine:知道了! Engine 默默地将 requests (Downloader Middlewares中process_request进行处理) 发送给 Downloader (下载器)
5、Downloader:Engine,你看,我下载好了,快夸夸我。Downloader 将 response (Downloader Middlewares中process_response进行处理) 发送给 Engine (引擎)
6、Engine:知道了!Engine 将 response 交给 spider (爬虫)
7、Spider:Engine,Engine 我处理好了。Spider 将 item 以及下一个 requests 发送给Engine (引擎)
8、Engine:知道了!Engine 将 item 交给 Item Pipeline (管道) 过滤储存,将下一个 requests 发送给 Scheduler (调度器)
如果你只有一个链接需要抓取,那么在第8步的时候 Engine 将 item 交给 Item Pipeline 后,Engine就会停止,直至 Item Pipeline处理完所有的 item ,整个程序才算停止。在后面我会举例子证明这一点。如果你有很多的链接需要抓取,那么这个流程就是:1 ——> 2 ——> 3 ——> 4 ——> 5 ——> 6 ——> 7 ——> 8 ——> 3 ——> 4 ——> 5 ——> 6 ——> 7 ——> 8 ——> 3 ——> … … ——> 8 。直至所有 item 处理完成,程序停止。
文中提到的网站
Scrapy | github, Scrapy | 官方社区, Scrapy | 官方文档, pypi | Twisted, 清华大学开源软件镜像站, 百度经验 | anaconda清华源更换